At last, an explanation for humanists that is actually a gentle introduction. Suggestions for improving this tutorial are greatly appreciated.
When you search the web, you pretty much just search "the full text" of what's out there. That means you can find individual words or phrases anywhere they occur in a webpage. Certain databases and subscription-only electronic resources also let you search or browse metadata fields like title, author, and date of publication, but even in these cases the body of the document is still one big mass. So what if:
For all of these cases, you can't rely on something that just stores "the full text." You need a system that allows annotations to label the various components of the text—in the examples above, these would include quotations, personal names, and place names.
This is what XML does for you.
XML ("Extensible Markup Language") is an open and non-proprietary standard that specifies "a simple data format that balances the needs of people to read/write data with the needs of machines to read/write data."[1] The standard is open in that anyone may use it freely without paying royalties. It's non-proprietary in that no one person or corporation controls it. Its open and non-proprietary nature ensures that XML documents will be readable in the long run because they not dependent on any particular hardware or software to read them. And the fact that it's a standard means that everyone agrees on the format, allowing for XML data to be shared easily and used by others because everyone knows what to expect when they receive it.
In computing, XML is often used as a format for interchanging bits of structured data (like product sales information) between computers, but its structure lends itself to the interchange of whole digital documents as well. In fact, the term "markup language" comes from the publishing term to mark up, meaning to annotate sections of a text for proper typesetting. XML evolved from SGML ("Standard Generalized Markup Language"), which was an effort to come up with a standard way of annotating these documents.
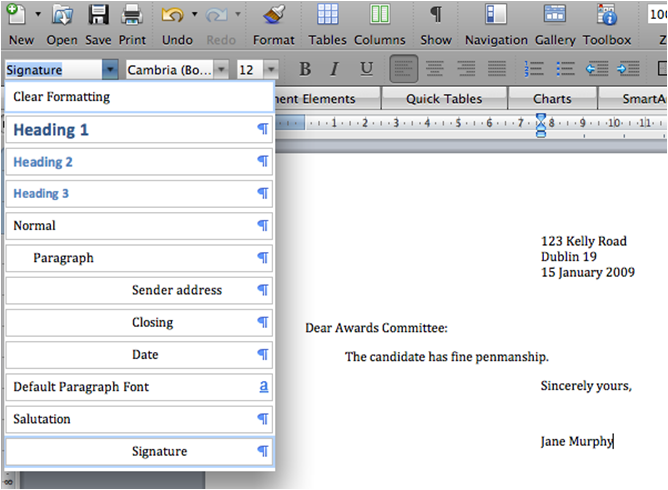
Let's stick with publishing for a moment because the use case is straightforward. Have you ever used styles in Microsoft Word? (It's the most useful of Word's many underused features.) While Word has a few built-in styles, you can create a style for every component of your text that you'd like. For example:
If your Word document contained a whole set of such letters, you could change how a certain component of all your letters appears by redefining the style just once. For example, you can set the closing (like "Sincerely yours,") to have three blank lines after it, or you can have the signature ("Jane Murphy") appear in bold text. By using styles, you don't have to go through every letter to make this change manually.
XML is like word-processor styles on steroids. Instead of simply defining a list of styles and their appearance, you can:
The thing about the Extensible Markup Language is that it's not actually a language: it's a framework for creating specific markup languages that include a full syntax and lexicon.[3] So XML by itself doesn't specify the names of the "styles," their variants, or their order; only a particular markup language does this. There are lots of markup languages out there, freely available for use, so don't reinvent the wheel by creating your own. Not only is it a lot of work, but your documents won't be easily understood by others. As with human languages, there are advantages to using a dominant language.
Let's learn a bit of terminology. (Till now, we've been using the term "style" as in Microsoft Word, but they're not called this in XML and, in fact, this word means something very different in the XML world.)
XML marks the beginning and end of spans of text using tags, which are always surrounded by angle brackets:
<sentence>This is a sentence.</sentence>
The above example has both an opening tag and a closing tag. The closing tag always has a slash in it.
Tags must nest properly–that is, you must always close the last tag you opened before closing a previous one. If you don't nest properly, you get what's often called overlap. For example, this is wrong:
<sentence>Overlap is <emphasis>not allowed!</sentence></emphasis>
The problem here is that the emphasis tag needs to be closed before the sentence tag. Here's the correct way to do it:
<sentence>Overlap is <emphasis>not allowed!</emphasis></sentence>
Technically, tags are instances of elements, which usually have content between the opening and closing tags.
Elements can also have attributes with their own values. The examples below use the sentence element and the type and xml:lang attributes. These two attributes have values in between quotation marks (inverted commas).
<sentence>This is a sentence.</sentence><sentence type="declarative">This is a sentence.</sentence><sentence type="declarative" xml:lang="ru">Это предложение.</sentence><sentence type="interrogative">Is this is a sentence?</sentence>
Some elements are empty—they have no content. They can be written in either of the following ways:
<milestone type="pagebreak"></milestone><milestone type="pagebreak"/>
You may be thinking that this all looks a lot like HTML. HTML is a specific implementation of XML (well, actually, its predecessor SGML) that has predefined elements and attributes for the common components of webpages. You can't create your own elements, so its usefulness is limited.
XML is often thought of as a tree structure:
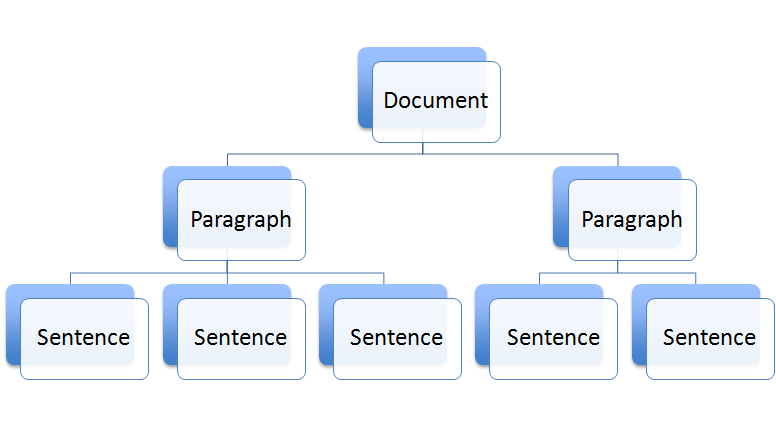
When discussing XML, we use family tree terms: parent, child, sibling, ancestor, and descendent. Remember, in XML, all elements must nest properly! So in a tree diagram, the lines never cross, and in your XML document, you always close a tag before closing its parent tag.
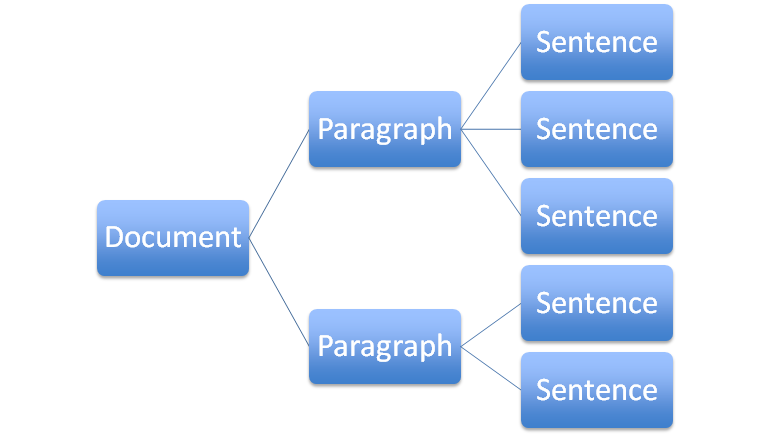
Here's another way to visualize that tree:
When you open an XML file using a text editor or XML editor (a special text editor for creating and editing XML documents), you'll see something like this:

The first line of every XML file is called the declaration. For this document, it looks like:
<?xml version="1.0" encoding="UTF-8" ?>
It allows a processor to understand details about what kind of file this is. There may be additional lines at the beginning of your XML that give more information about it (for example, a link to a separate file, called a stylesheet, that controls how the document looks when displayed online). You will need to understand these if you plan to create XML, but if you just need to look at or edit existing files, you may be able to ignore them.
Notice that this XML editor shows the tree structure to the left and the XML document itself to the right.
If you're using a particular markup language, how do you make sure you use only the proper element and attribute names, properly nested? You validate your XML document against a schema, which contains the the grammar (and vocabulary) for that particular markup language. There a few different formats for schemas, the most well-known of which in the world of documents (as opposed to data) is a DTD (Document Type Definition). More specifically, the schema specifies:
Do you really need to validate your documents to make sure they follow such rules? Doing so helps you prevent errors in creating your XML, and if you ensure that all of your documents follow a consistent structure, you can, for example, easily find all personal or place names, or make sure all of your letters have both senders and recipients. XML is helpful for publishers trying to create consistent output (since you can associate a particular formatting style with a particular element), and it's helpful for scholars using the markup to perform searches that can't be done just by "searching the full text."
XML works very well for marking up regularly structured texts for which you wish to maintain a consistent structure, such as whitepapers, scholarly journal articles, sonnets, and tax forms. It works less well for representing creative works that violate conventions, such as postmodern novels and certain non-verse poetry. Representing primary source documents can also be quite difficult. However, there isn't really a better way to represent these difficult cases and still process them with a computer than by using XML, and for the kinds of documents that humanists are concerned with, the de facto standard markup language, recommended by the Modern Language Association and the National Endowment for the Humanities in the US, is the Text Encoding Initiative (TEI) Guidelines. The Guidelines are massive and overwhelming, with much detail about various ways you might handle primary source documents and specific annotations needed only for scholarly analysis. People sometimes find TEI more frustrating than markup languages used in other domains because it isn't a finite standard but rather a framework that is designed to be customized for your needs, and because it often provides more than one way to do what appears to be the same thing in order to accommodate the needs of different scholars. Still, that powerful framework for customization, which allows local changes to be kept in sync with modifications to the base system, allows users to meet specific needs in a text encoding project while striving toward interoperability with the larger body of scholarly literature.
Want to learn more? See TEI by Example for some examples of XML in use, or see What is XML and why should humanities scholars care? for a more in-depth version of what's above.
[1] This quotation is often attributed to Dan Connolly of the World Wide Web Consortium (W3C), the standards group that maintains the XML specification.
[2] Microsoft Word allows character styles within paragraph styles but no more than these two levels of nesting.
[3] For the linguistically inclined, XML is akin to Universal Grammar in Chomskyan linguistics: a basic framework, with a few inviolable rules, on which a particular language is built.

This work is licensed under a Creative Commons Attribution 4.0 International License.
Last updated Thursday, 31-Oct-2019 14:00:34 EDT
